数据一致性 Consistency
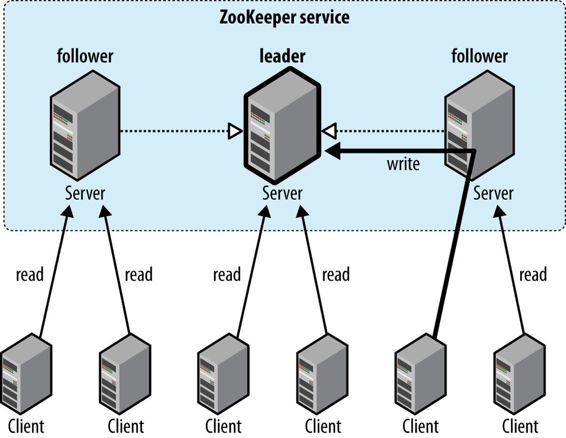
理解了ZooKeeper的实现原理,有助于理解ZooKeeper如何保证数据的一致性。就像字面上理解的“leader”和“follower”的意思一样,在ensemble中follower的update操作会滞后于leader的update完成。事实的结果使我们在提交更新数据之前,不必在每一台ZooKeeper服务器上执行持久化变更数据,而是仅需在主服务器上执行持久化变更数据。ZooKeeper客户端的最佳实践是全部链接到follower上。然而客户端是有可能连接到leader上的,并且客户端控制不了这个选择,甚至客户端并不知道连接到了follower还是leader。下图所示,读操作向follower请求即可,而写操作由leader来提交。
每一个对znode树的更新操作,都会被赋予一个全局唯一的ID,我们称之为zxid(ZooKeeper Transaction ID)。更新操作的ID按照发生的时间顺序升序排序。例如,小于,那么的操作就早于操作。
ZooKeeper在数据一致性上实现了如下几个方面:
顺序一致性
从客户端提交的更新操作是按照先后循序排序的。例如,如果一个客户端将一个znode z赋值为a,然后又将z的值改变成b,那么在这个过程中不会有客户端在z的值变为b后,取到的值是a。
原子性
更新操作的结果不是失败就是成功。即,如果更新操作失败,其他的客户端是不会知道的。
系统视图唯一性
无论客户端连接到哪个服务器,都将看见唯一的系统视图。如果客户端在同一个会话中去连接一个新的服务器,那么他所看见的视图的状态不会比之前服务器上看见的更旧。当ensemble中的一个服务器宕机,客户端去尝试连接另外一台服务器时,如果这台服务器的状态旧于之前宕机的服务器,那么服务器将不会接受客户端的连接请求,直到服务器的状态赶上之前宕机的服务器为止。
持久性
一旦更新操作成功,数据将被持久化到服务器上,并且不能撤销。所以服务器宕机重启,也不会影响数据。
时效性
系统视图的状态更新的延迟时间是有一个上限的,最多不过几十秒。如果服务器的状态落后于其他服务器太多,ZooKeeper会宁可关闭这个服务器上的服务,强制客户端去连接一个状态更新的服务器。
从执行效率上考虑,读操作的目标是内存中的缓存数据,并且读操作不会参与到写操作的全局排序中。这就会引起客户端在读取ZooKeeper的状态时产生不一致。例如,A客户端将znode z的值由改变成,然后通知客户端B去读取z的值,但是B读取到的值是,而不是修改后的。为了阻止这种情况出现,B在读取z的值之前,需要调用sync方法。sync方法会强制B连接的服务器状态与leader的状态同步,这样B在读取z的值就是A重新更改过的值了。
| 注意 |
|---|
sync操作只在异步调用时才可用,原因是你不需要等待操作结束再去执行其他的操作。因此,ZooKeeper保证所有的子操作都会在sync结束后再执行,甚至在sync操作之前发出的操作请求也不例外。 |