Data Format
The data we will use is from the National Climatic Data Center, or NCDC. The data i stored using a line-oriented ASCII format, in which each line is a record. The forma supports a rich set of meteorological elements, many of which are optional or wit variable data lengths. For simplicity, we focus on the basic elements, such as temperature which are always present and are of fixed width.
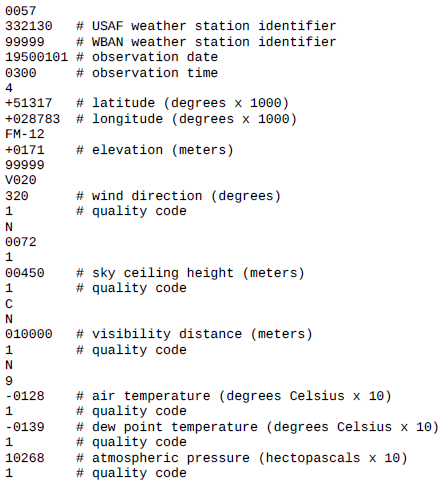
Example 2-1 shows a sample line with some of the salient fields annotated. The line ha been split into multiple lines to show each field; in the real file, fields are packed into on line with no delimiters.
Example 2-1. Format of a National Climatic Data Center record
Datafiles are organized by date and weather station. There is a directory for each yea from 1901 to 2001, each containing a gzipped file for each weather station with it readings for that year. For example, here are the first entries for 1990:
% ls raw/1990 | head
010010-99999-1990.gz
010014-99999-1990.gz
010015-99999-1990.gz
010016-99999-1990.gz
010017-99999-1990.gz
010030-99999-1990.gz
010040-99999-1990.gz
010080-99999-1990.gz
010100-99999-1990.gz
010150-99999-1990.gz
There are tens of thousands of weather stations, so the whole dataset is made up of a larg number of relatively small files. It’s generally easier and more efficient to process smaller number of relatively large files, so the data was preprocessed so that each year’ readings were concatenated into a single file. (The means by which this was carried out i described in Appendix C.)